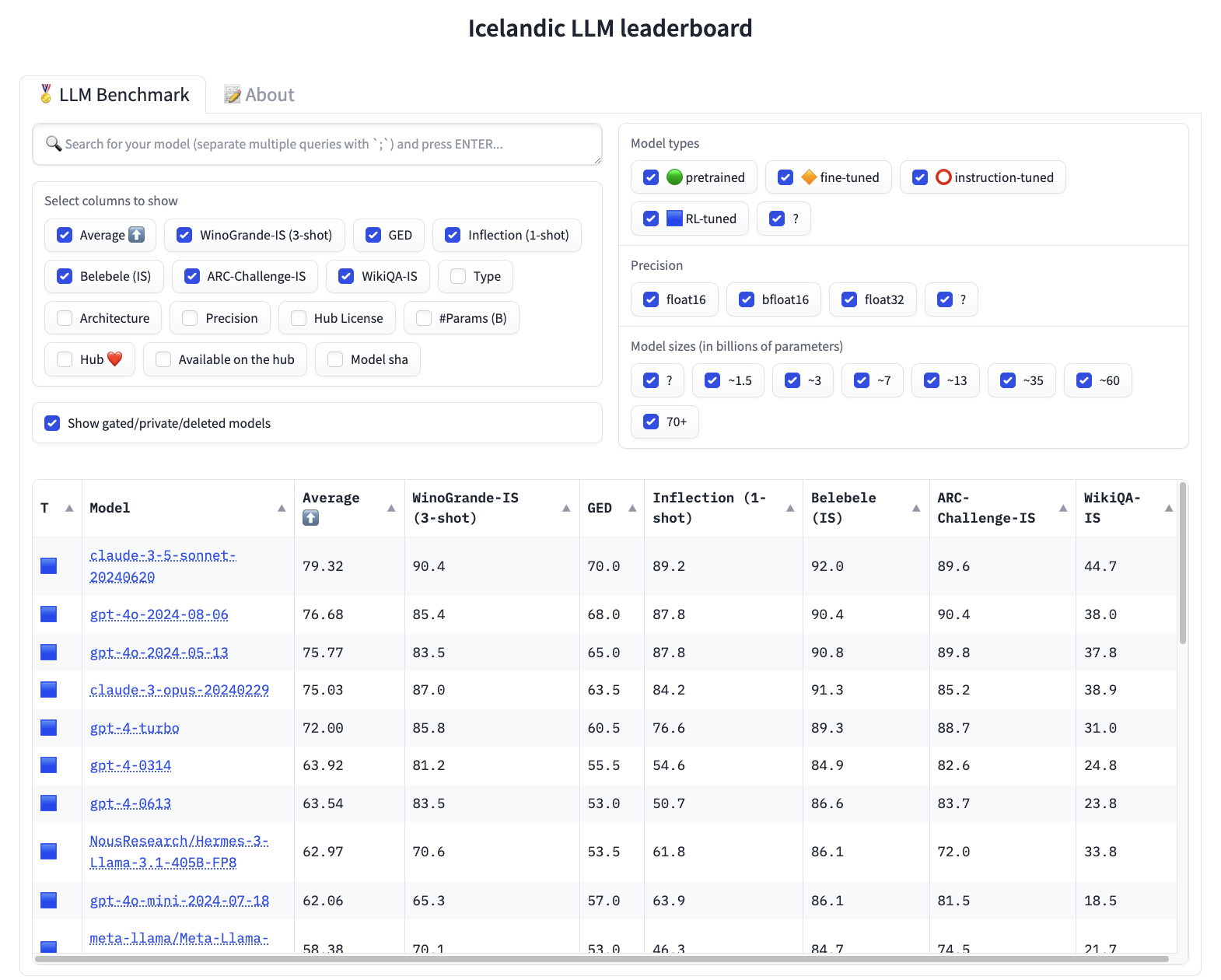
Við í Miðeind erum spennt að kynna nýja stigatöflu sem metur frammistöðu risamállíkana á íslenskum prófum. Stigataflan er mikilvægt tæki til að fylgjast með þróun gervigreindartækninnar á íslensku og getur hjálpað við að velja rétt líkön í verkin. Við munum fjalla um mikilvægi íslenskra mæliprófa, útskýra áskoranir við prófun risamállíkana og kynna íslensku prófin sex sem við leggjum fyrir líkönin. Stigatöfluna má nálgast á vef Hugging Face:
https://huggingface.co/spaces/mideind/icelandic-llm-leaderboard
Mállíkön eru nýtt á ótal ólíka vegu. Sum gegna hlutverki spjallmennis í bankaþjónustu, önnur eru sett í hlutverk einkaritara og enn önnur eru látin lesa yfir og þýða skáldsögur. Forsenda allra þessara notkunartilvika er að líkanið skilji umbeðið tungumál og geti tjáð sig á því á fullnægjandi hátt.
Mikil áhersla hefur hingað til verið lögð á að smíða próf á ensku, enda var hæfni á öðrum tungumálum framan af afar ábótavant. Því hafa smærri mál eins og íslenska orðið út undan og okkur vantar oft sárlega próf sem meta hæfni líkana á verkefnum sem almennt þykja leyst fyrir stærri tungumál.
Á sama hátt og bandarískur lögfræðingur ætti líklega erfitt með að veita lagaráðgjöf á íslensku getur verið varasamt að gera ráð fyrir að hæfni mállíkana á ensku yfirfærist á íslensku.
Til að hægt sé að velja rétt líkön í verkin er því rík þörf á fjölbreyttum prófum sem mæla íslenskufærni, en líka til að meta hvaða hæfni núverandi kynslóð líkana skortir svo hægt sé að leggjast í úrbætur.
Við gerð sjálfvirkra prófa fyrir mállíkön stöndum við frammi fyrir svipuðu vandamáli og margir kennarar kannast líklega við. Krossapróf er auðvelt að fara yfir og gefa einkunn fyrir en er erfiðara að semja, auk þess sem þau gefa þrönga mynd af þekkingu próftakans. Aftur á móti er oft auðveldara að semja spurningar með skriflegum svörum og þær framkalla annars konar þekkingu. Hins vegar getur reynst töluvert erfiðara að fara yfir og gefa einkunn fyrir svör, sérstaklega á sjálfvirkan máta.
Suma hæfni mállíkana er líka nær ómögulegt að prófa með krossaspurningum, eins og til dæmis málmyndunargæði. Það liggur í hlutarins eðli að til að meta gæði myndaðs máls þarf líkanið jú að mynda það.
Undanfarin ár hefur líkönunum fleygt fram og samhliða hafa kröfur um erfiðleikastig prófanna aukist. Sem dæmi má nefna MMLU [1], próf sem metur þekkingu líkana á menntaskóla- og grunnháskólastigi innan ýmissa fræðigreina. Þegar það kom til sögunnar árið 2020 reyndist prófið einkar erfitt fyrir mállíkön þess tíma og engin náðu fleiri en 50% stiga. Mállíkön dagsins í dag fara hins vegar létt með það og fá mörg hver nærri 90% [2]. GPQA-prófið [3] var síðar birt árið 2023 og mælir enn sérhæfðari þekkingu upp að meistara- og doktorsstigi háskóla. Það reynist enn snúið og bestu líkön dagsins í dag fá undir 80% stiga [2].
Yfirleitt er talað um að próf sé „leyst“ þegar líkan fær hærra en 90-95%. Oft innihalda prófin einhver gölluð dæmi og betrumbætur umfram svo háa einkunn verða því minna og minna markverðar. Þá hættir prófið að vera góður prófsteinn fyrir framfarir og nýs erfiðara prófs er þarfnast.
Íslenska stigataflan samanstendur af sex prófum. Þau voru valin til að gefa sem heildstæðasta mynd af íslenskufærni mállíkana og meta ólíka þætti eins og málskilning, menningarþekkingu og málfræði. Prófin eru blanda af þýddum alþjóðlegum prófum og sérstaklega þróuðum íslenskum prófum.
Winogrande er ætlað að meta almenna ályktunarhæfni líkana og leysa úr tvíræðni í tungumáli út frá samhengi, nokkuð sem ætti að vera mannfólki afar náttúrulegt. Við þýddum og staðfærðum þúsund dæmi úr upprunalegu útgáfu prófsins frá Allen Institute for AI [4]. Hvert dæmi er sett upp sem málsgrein sem inniheldur eyðu og tvo valkosti fyrir eyðuna sem báðir eru málfræðilega réttir en aðeins annar passar inn í samhengi setningarinnar. Þetta krefst þess að líkanið skilji samhengi og hafi almenna ályktunarhæfni. Dæmi:
„Barnið kom bókinni ekki fyrir í töskunni því _ var of stór“. Hvort væri réttara að setja í eyðuna „bókin“ eða „taskan“?
Rétt svar: „bókin“
Fallbeygingarprófið metur hæfni líkana til að beygja nafnliði í öllum föllum, eintölu og fleirtölu. Það er þannig sett upp að líkani er gefinn nafnliður sem inniheldur lýsingarorð og nafnorð og gert að svara til baka beygingarmynd hans í ákveðinni tölu og falli. Dæmi:
Hver er beygingarmynd nafnliðarins „rakleidd járnhönd“ í þolfalli fleirtölu án greinis?
Rétt svar: „rakleiddar járnhendur“
WikipediaQA er mælipróf sem er ætlað að meta þekkingu líkana á íslenskri menningu, hefðum og sögu. Spurningar og svör voru unnin sjálfvirkt úr íslenska hluta Wikipediu með hjálp GPT-4o og síðan handyfirfarin af manneskju. Spurningarnar eru lagðar fyrir líkanið sem á að prófa og það svarar með einni eða fleiri setningum. Svörin eru síðan borin saman við staðalsvar með því að láta GPT-4o meta hvort gefna svarið sé efnislega rétt. Dæmi:
Hvað var Kolviðarhóll, sem gegndi hlutverki í íslenskri ferðamenningu á 19. og 20. öld?
Rétt svar: Áningarstaður ferðamanna
Grammatical error detection (GED) mælir greiningarhæfni líkana í málfarsvillum. Þetta gerum við með því að gefa líkaninu 100 leiðréttar og 100 óleiðréttar setningar úr Íslensku villumálheildinni og biðjum það að merkja hvort hver stök setning innihaldi villur eða ekki. Dæmi:
Setning: „Þetta bendir til þess að kvikan sé þarna á einhverrri lágréttri hreyfingu og þetta svipar mjög til þess sem gerðist fyrir gosið.“
Rétt svar: Inniheldur villu. Hér má finna þrjár villur: Orðið „einhverri“ er ranglega ritað með þremur errum, „lágréttri“ ætti að vera „láréttri“ og „þetta svipar“ ætti að vera „þessu svipar“.
Belebele er lesskilningspróf frá Facebook [5] þar sem verkefnið er að lesa texta og svara krossaspurningum um innihald hans. Dæmi:
Lestu fyrst þennan texta: „Lodin sagði einnig að embættismenn hefðu ákveðið að hætta við úrslitaviðureignina í kostnaðarskyni fyrir Afgani og vegna öryggisáhættu samfara öðrum kosningum. Diplómatar sögðust hafa fundið út að afganska stjórnarskráin væri nógu óljós til að sjá að ekki væri þörf á lokakosningunni. Þetta stangast á við fyrri fregnir sem sögðu að ef hætta yrði við viðbótarumferðina væri það brot gegn stjórnarskránni.“
Samkvæmt því sem fram kemur í kaflanum, hver þessara ástæðna var ekki notuð til að útskýra af hverju hætt var við úrslitaviðureignina?
A: Öryggisáhætta
B: Ósamræmi í stjórnarskrá
C: Hár kostnaður
D: Óljós stjórnarskrá
Rétt svar: B
AI2 Reasoning Challenge (ARC) er mælipróf frá Allen Institute for AI [6]. Prófið samanstendur af krossaspurningum um vísindi á grunnskólastigi sem krefjast bæði almennrar þekkingar og rökhugsunar til að svara rétt. Spurningarnar voru valdar sérstaklega til að vera krefjandi fyrir mállíkön þegar prófið var smíðað árið 2018 en eru að mestu orðnar auðveldar fyrir bestu mállíkön í dag á ensku. Við vélþýddum prófið yfir á íslensku með hjálp Claude 3.5 Sonnet. Hér er dæmi um spurningu:
Sem hluti af tilraun tekur geimfari með sér vog til tunglsins og vigtast. Vogin sýnir 31 pund. Ef geimfarinn er um 84 kíló að massa, hver eru líkleg þyngd og massi geimfarans þegar hann stendur á jörðinni?
A: 31 pund og 14 kíló
B: 31 pund og 84 kíló
C: 186 pund og 14 kíló
D: 186 pund og 84 kíló
Rétt svar: D
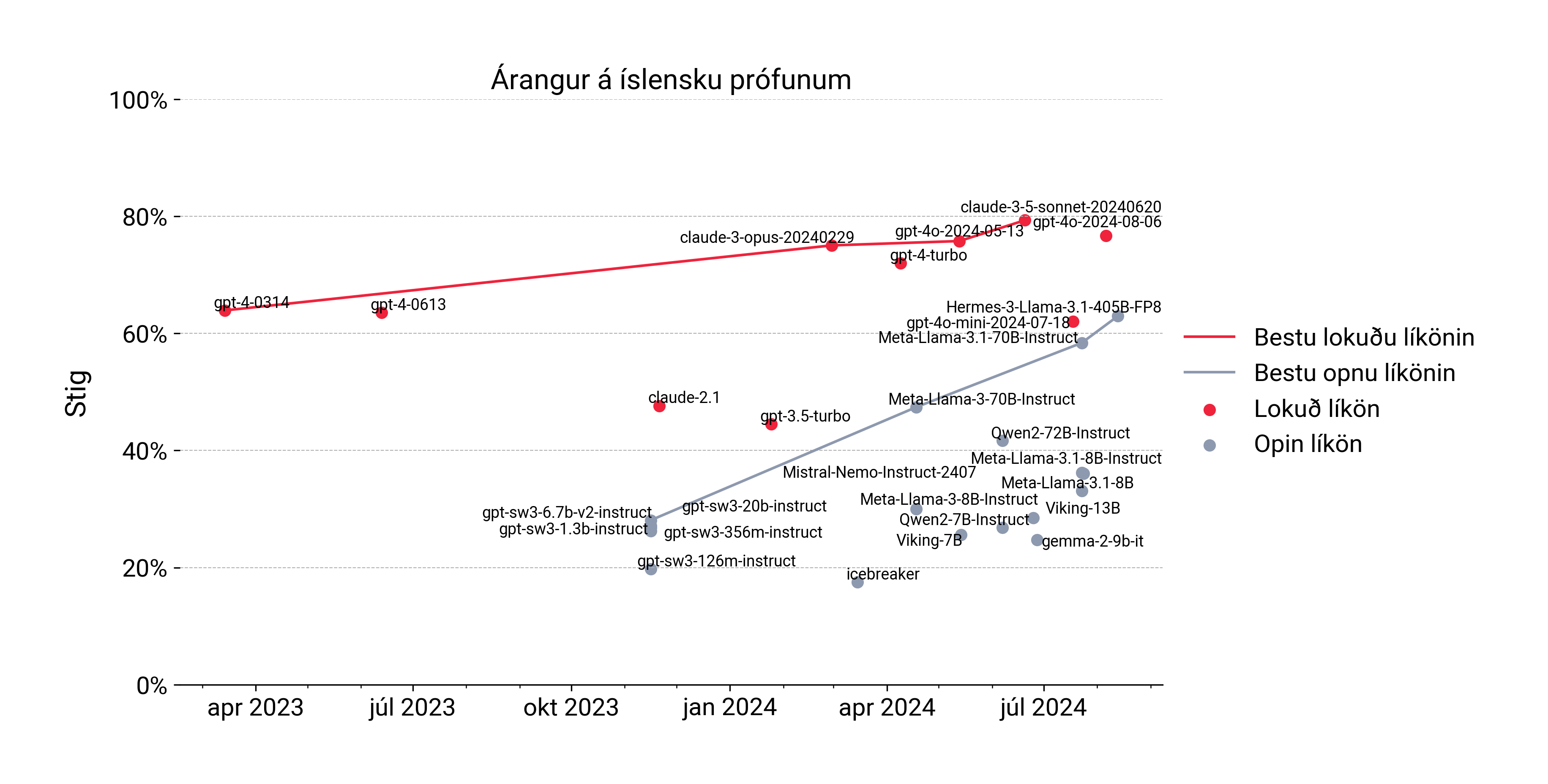
Með því að líta á þróun stigatöflunnar yfir tíma sjáum við skýra mynd af yfirburðum lokaðra líkana á íslensku prófunum. Jafnvel fyrsta útgáfa GPT-4 frá því í mars 2023 slær hæfasta opna líkaninu Llama 3.1 við. Hins vegar virðast opnu líkönin vera á töluverðri siglingu og það má vonandi búast við að ekki hægi mikið á bætingu þeirra næstu ár. Einnig má hafa í huga að opnu líkönin sem við birtum á stigatöflunni eru að öllum líkindum töluvert smærri en lokuðu líkönin sem OpenAI og Anthropic hafa í rekstri og því getur samanburðurinn ekki alveg talist sanngjarn.
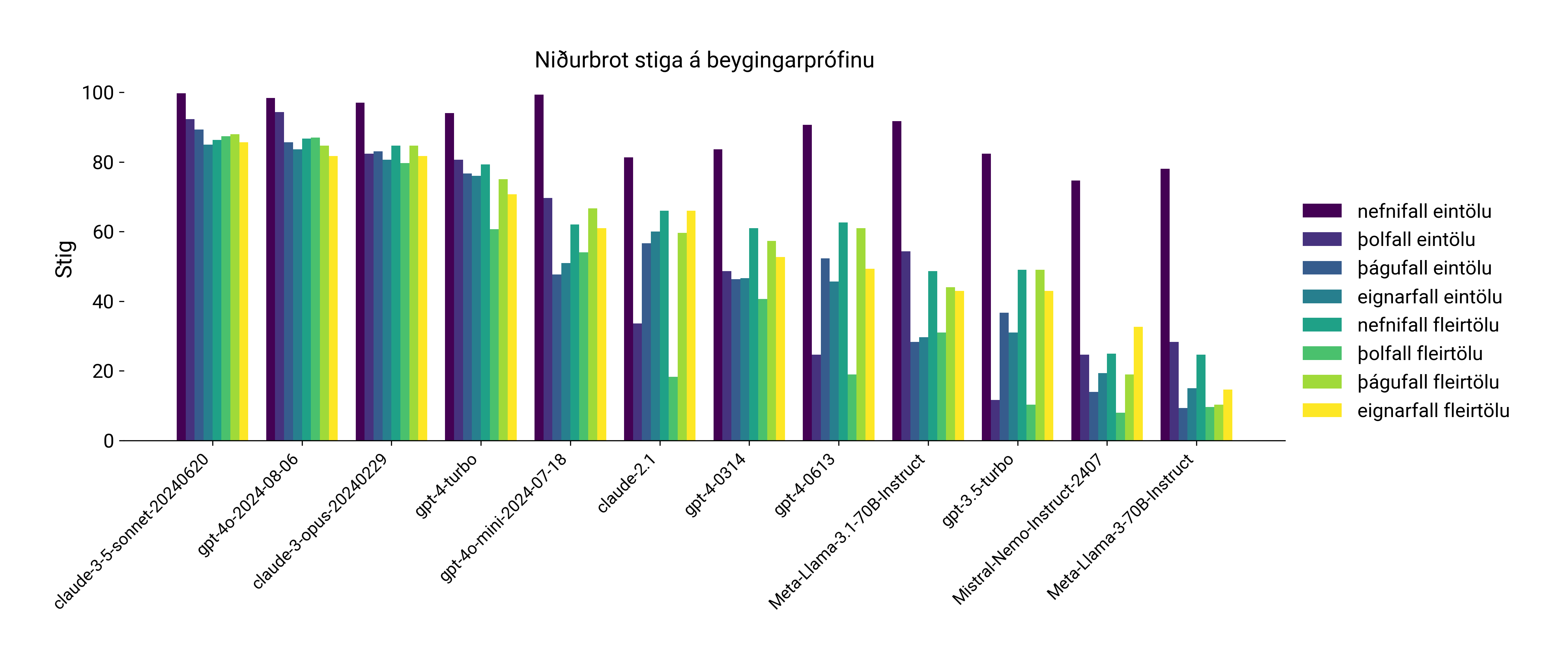
Til gamans má líta betur á niðurstöðurnar úr fallbeygingarprófinu á myndinni að neðan. Þar sjáum við valin líkön af stigatöflunni þar sem stigin eru brotin niður eftir tölu og falli. Nefnifall eintölu vefst lítið fyrir líkönunum enda er sú mynd gefin í framsetningu dæmanna. Hins vegar hnignar færni í aukaföllum og fleirtölu hratt eftir því sem við förum niður stigatöfluna og þá virðist þolfall fleirtölu sérstaklega snúið.
Stigataflan sem við höfum kynnt hér veitir mikilvæga innsýn í getu mállíkana í íslensku. Þó er vert að hafa í huga að prófin ná ekki yfir alla þætti íslenskufærni og því ætti að taka niðurstöðunum með ákveðnum fyrirvara. Sér í lagi vantar próf sem metur málmyndunargæði með markvissum hætti. Við stefnum að því að bæta við fleiri prófum og uppfæra töfluna reglulega til að gefa sem nákvæmasta mynd af stöðunni. Við hlökkum til að fylgjast með þróuninni enda er þetta verkefni mikilvægt fyrir framtíð íslenskunnar í heimi gervigreindar.
[1] https://arxiv.org/abs/2009.03300
[2] https://openai.com/index/learning-to-reason-with-llms/
[3] https://arxiv.org/abs/2311.12022
[4] https://winogrande.allenai.org/
[5] https://ai.meta.com/research/publications/the-belebele-benchmark-a-parallel-reading-comprehension-dataset-in-122-language-variants/
[6] https://arxiv.org/abs/1803.05457