Málfríður is one of the solutions found within Málstaður. It is a powerful proofreading tool that can help you write better texts and communicate what you want to say more effectively. But how does Málfríður work? How is it different from other spell-checking software for Icelandic? And why does it sometimes make mistakes? Here we will go through how Málfríður manages to correct everything from typos to more complex language issues, discuss the data used to train it, and introduce the neural network behind it.
Málfríður uses artificial intelligence to correct errors in language use, spelling, and punctuation in Icelandic. You can write text directly into its interface and have it proofread as you go, or you can paste text and have Málfríður review it. It's useful both for those who need just a light review of their text and for those who want more assistance.
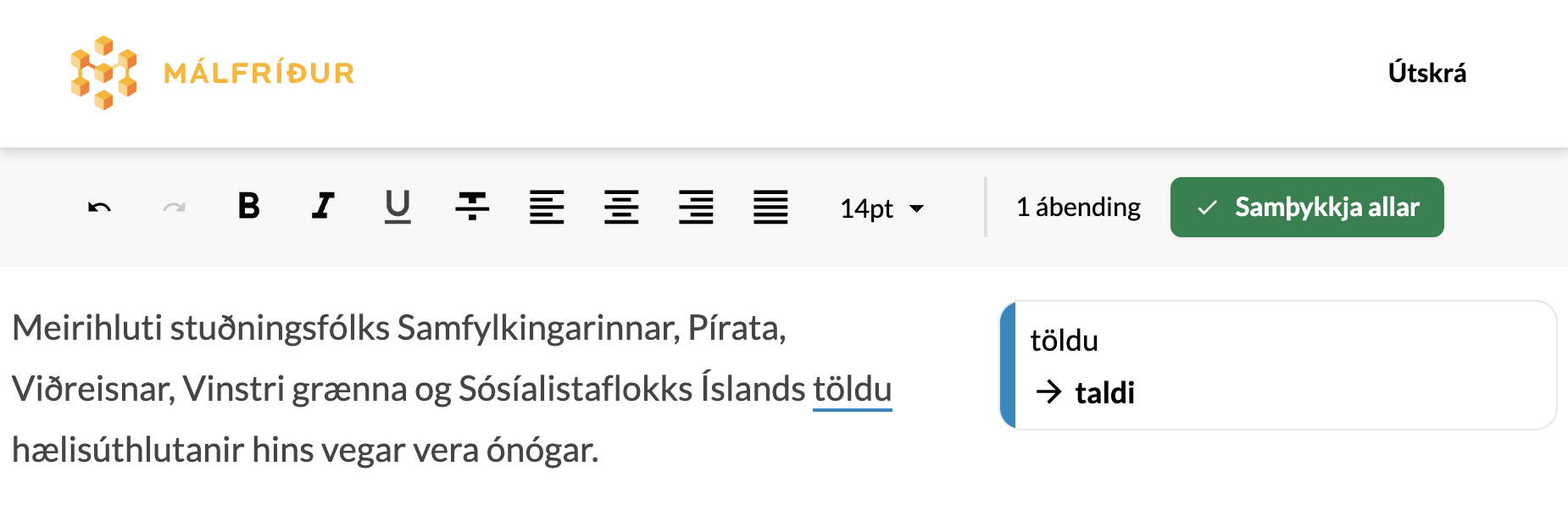
Málfríður is versatile and corrects various language issues. For example, people often struggle with inflecting long noun phrases as in this example, but Málfríður makes light work of it:
Málfríður is also skilled at ensuring that the subjunctive mood is used according to linguistic conventions.
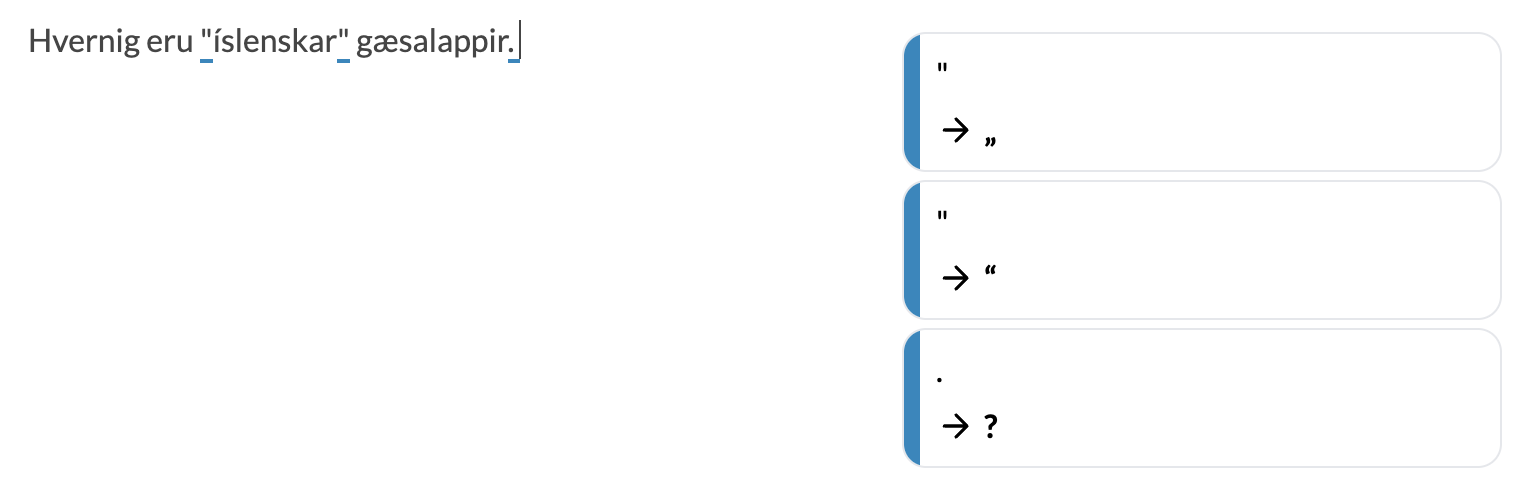
Málfríður also pays attention to punctuation and makes sure that quotation marks are the Icelandic ones.
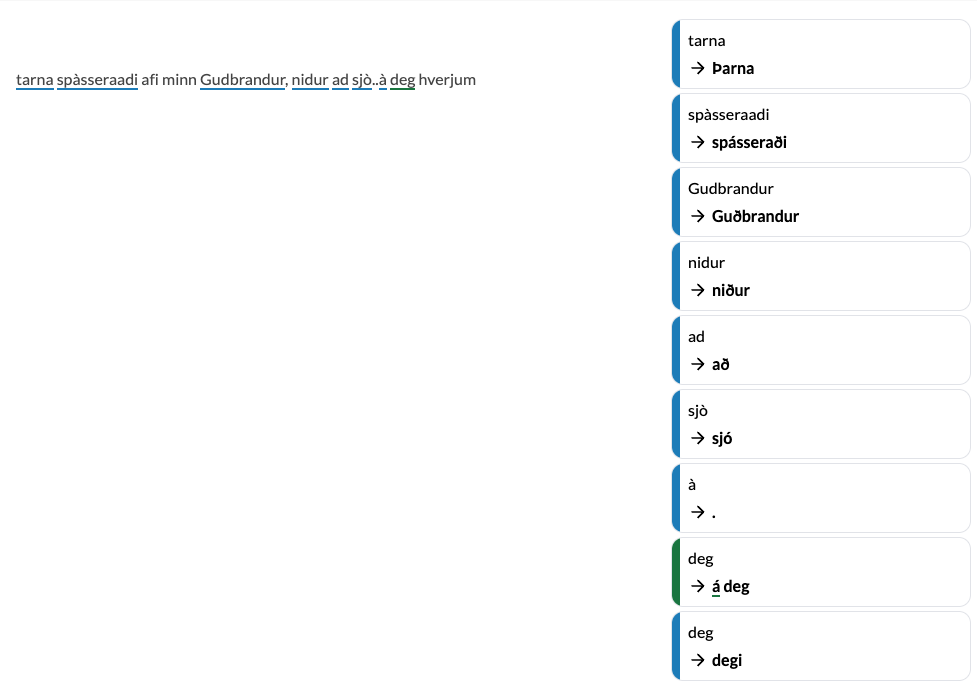
For people with dyslexia or who have difficulty writing text in accordance with writing conventions, it can be very useful to have Málfríður proofread it. Málfríður can handle all kinds of texts, even those where many changes are needed.
Málfríður can also correct various other language issues such as the dative tendency ("mér hlakkar"), one/two words ("heildar fjöldi"), ng/nk ("einginn") and much more. This doesn't mean, however, that it has been programmed with countless rules about the Icelandic language, because unlike most proofreading software for Icelandic, Málfríður is data-driven, not rule-driven. Before we look more closely at what that means, let's examine how more traditional programs correct errors.
Until now, proofreading software for Icelandic has used rules, patterns, and lists of common errors to determine what should be corrected. They usually have a database of correctly spelled words behind them, such as the Inflectional Database (BÍN), and if they encounter a word that's not on the list, they have various methods, rules, patterns, and lists of common errors to apply to try to correct the word. They look at, for example, edit distance. This means that when a word appears that is not in the program's database, it calculates how many steps it would take to change it into a word that is in the database. If the program encounters the word "sjómvarp", for instance, it looks up in the database and finds the valid word closest to it, "sjónvarp". The edit distance between these words is 1, because it only takes one substitution (m→n) to change the misspelled word into a valid word.
This method, along with using lists of errors known to be frequently made by people (systkyni → systkini, etc.) and various patterns with limited context (á næsta leyti → á næsta leiti, að ýmsu leiti → að ýmsu leyti), takes these programs very far, and they are very useful for finding various errors in texts.
However, these programs usually don't take into account the broader context of the text, or its meaning, and therefore have more difficulty correcting inconsistencies in gender and number ("hann er búin") or when all the words are valid Icelandic words, as in the following example:
„Samkvæmt móðurinn var hún heimavinnandi og sá um börnin …“
Since all the words in the sentence exist in Icelandic, such programs have no basis for changing "móðurinn" to "móðurinni".
Yfirlestur is Miðeind's previous error correction solution, which was originally developed as part of the government's language technology program. This solution uses rules, patterns, and lists like previous solutions but also utilizes our powerful language analysis functionality to analyze the text into sentence trees, thus enabling the correction of complex syntactic issues such as the dative tendency ("smiðnum vantar hamar"). Another clear strength of Yfirlestur is the ability to explain the error and even refer to writing rules.
Now Málfríður has taken over from Yfirlestur, but many features from Yfirlestur could be further transferred to Málfríður, and this is one of the things we're interested in implementing in the future. The work put into Yfirlestur has also been very useful in the development of Málfríður, even though the approach is different.
Let's now look under the hood of Málfríður and see how it does things differently from previous proofreading software.
What do we mean by saying Málfríður is data-driven? Well, instead of teaching Málfríður rules to follow to correct errors, we have shown it countless examples of texts with errors and then corrections to them.
Málfríður is a neural network model, and these need to be fed enough data to learn patterns from them. Neural network models for correction are essentially computational models that we feed with millions of text snippets containing all kinds of errors we want it to learn to correct.
Here's an example of a text snippet for training a neural network
Afi mig for á honum rauð einhvað suðra bæinn að sækja bæði sykur og brauð, sit á hvoru tæi.
which corrected looks like this:
Afi minn fór á honum Rauð eitthvað suður á bæinn að sækja bæði sykur og brauð, sitt af hvoru tagi.
Then the model is trained, which happens through a process that's a bit like when a person learns a new language and is described better below.
In an assessment that Miðeind conducted on news texts from Iceland's main news outlets, the results showed that in about 90% of cases where an error is present, Málfríður provides correct and useful corrections, and that in the vast majority of the published news articles, there were one or more errors that it spotted and corrected correctly.
The examples above show some instances where Málfríður can undoubtedly be of great use. One advantage of Málfríður that might not be obvious at first glance is that it has context. It is trained on several sentences at a time, and can thus correct across sentences, which is useful in examples like this:
Stelpurnar byrjuðu á námskeiðinu í gær. Þeim hafði hlakkað lengi til þess.
where in formal language style, the nominative case should be used instead of the dative, and the correction needs context from the previous sentence:
Stelpurnar byrjuðu á námskeiðinu í gær. Þær höfðu hlakkað lengi til þess.
There are, however, limits to how long context can be, with the methods applied here, and as of yet, Málfríður doesn't have context long enough to harmonize vocabulary across an entire essay, for example.
Málfríður has some language understanding, needed for example for correcting the following texts where "vegg" means "wall" (accusative) and "veg" means "road" (accusative).
Við keyrðum um langan vegg til að komast á leiðarenda.
Hún hengdi myndina upp á veg.
The neural network behind Málfríður is not large enough to have a very deep understanding of meaning, so in more complex examples where meaning matters, it doesn't always manage to provide a correction.
Málfríður also makes other mistakes. It can't always correct errors in words that it has rarely or never seen in the training data (e.g., "heimagegnt", which should be "heimangengt").
One thing that might come as a surprise is that it's not possible to ensure that Málfríður corrects the same word in the same way in different sentences. This is because it uses probability calculations each time to determine whether it should change the text, and that calculation can differ depending on the surrounding text. Málfríður is well-trained enough to deliver the same corrections for the same errors most of the time, but sometimes it's not quite sure and then skips the correction. Therefore, the behavior is not predictable like it is with proofreading software that relies on rules and performs the same way each time.
Málfríður also can't (as of now) provide explanations for its decisions, it just either corrects or doesn't. Málfríður uses probabilities to assess whether a particular item should be corrected, and sometimes isn't quite "sure" enough, and so doesn't correct it. In our experiments, if we look behind the scenes, we can often see that Málfríður knows something is wrong with the text, but just doesn't know exactly which direction to go in correcting it. Sometimes Málfríður also goes in the wrong direction when correcting, and then it's often the language understanding that's lacking; this is not a person with "common sense" but a computational model.
We keep track of all these issues and are constantly working on improving Málfríður. For individual error types, we also have methods to add customized training data, so don't hesitate to contact us if you come across errors that Málfríður seems to systematically not know how to correct.
It takes an enormous amount of texts to train a neural network capable of correcting text well. For Málfríður, the texts need to be parallel, which means we need two versions of the text, the original text on one hand:
Hnn segir að firirtækið þarf að stánda straumaf tekjus5katti.
and on the other hand, the corrected version:
Hann segir að fyrirtækið þurfi að standa straum af tekjuskatti.
How do we get such data? We are fortunate that one collection of corrected Icelandic texts has been published, called The Icelandic Error Corpus. A corpus is a word for datasets used in language technology projects and can be of various types. The Icelandic Error Corpus was developed at the University of Iceland as part of the government's language technology program and contains Icelandic texts and their corrected versions. It also includes three more specialized corpora with texts by children, people with dyslexia, and people with Icelandic as a second language. These corpora are necessary data to train Málfríður on, so that it can learn how people write, and what might need to be corrected in texts.
But although the Icelandic Error Corpus is one of the larger corpora of its kind, much more data is needed to train a neural network like Málfríður. We also want to show the neural network examples of even more and more diverse errors than occur in the error corpus. Then we resort to creating "synthetic data". This way we can create a large amount of training data without having to put in a lot of work manually correcting texts.
We do this by taking texts that we consider to be mostly in good Icelandic, such as many texts in the Gigaword Corpus, which is yet another product from the government's language technology program: the largest collection of edited texts that exists for Icelandic. Then we add all kinds of errors into the texts, and scramble them in various ways:
Mig langar til að spyrja hæstv. ráðherra hvort hann sjái fyrir sér í framtíðinni að vatnsveitur sveitarfélaga verði í einkaeigu og að farið verði að hugsa um að selja þær, einkavæða þær.
resulting in a distorted version:
Mér langar til að spyrja hæstv. ráðherra hvort hann sér fyri rsér í framtíðinni að vatnsveitursveitarfélaga urðu í einkaeigu og að farið urðu að hugsa um að selja þær, einkavæða þær.
Then these two versions are used as training data, where the model learns to correct from the distorted version to the original one.
To produce as diverse errors as possible, we use many different methods. Some of the methods are very simple and random, while others use grammatical and syntactic information to change, for example, the inflection of words. Here are just a few examples of errors that are added to the synthetic data:
letters added, omitted, or substituted
spaces added or removed
punctuation changed
common errors added based on known error lists ("eitthvað" → "einhvað")
words repeated ("sem sem er")
words split up ("forsætis ráðherra")
case of words changed ("ég fór úr buxurnar")
prepositions changed ("af skornum skammti" → "að skornum skammti")
subjunctive mood changed to indicative mood ("ég held hann sé" → "ég held hann er")
imitating dative tendency ("krakkana langar" → "krökkunum langar")
This mix of more complex and simpler text distortion is a convenient way to create a large amount of data that can be used for training a model like Málfríður on different texts with all kinds of errors.
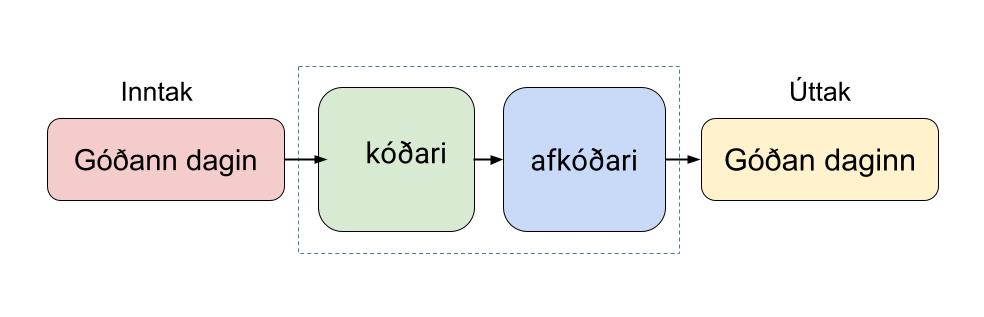
Let's now go a bit deeper into the training process. The neural network in Málfríður is a model that consists of two main components: an encoder and a decoder.
The training process is, in very broad terms, as follows:
The training data is divided into appropriate training batches, for example, several sentences together, which are fed into the model.
In the model, the encoder reads in a text snippet with errors and converts it into a digital representation (numbers). This is a necessary step because numbers are the language that computers can work with.
The decoder then takes this representation and tries to produce corrected text.
The model gets to see the correct version of the text and compares it with its own version. It then uses probability calculations to assess how well it performed and updates its knowledge accordingly.
At the beginning of training, the model makes many mistakes. But each time it makes a mistake, it receives feedback that it uses to adapt. This process is repeated millions of times with different examples. Gradually, the model learns patterns in how to correct common errors, correct spelling and grammar, and becomes increasingly accurate. This training can take many days, even weeks, depending on how large the neural network is and how much computing power is available.
After training, a correction model is created that can accept new text it has never seen before. The encoder converts the text into a digital representation and the decoder uses the knowledge it has gained in training to produce corrected text.
This type of neural network (encoder + decoder) has often been used to create programs that translate text between languages, and in fact, one can think of Málfríður as "translating" text containing errors into more readable text.
This type of neural network (encoder + decoder) has often been used to create programs that translate text between languages, and in fact, one can think of Málfríður as "translating" text containing errors into more readable text.
Various neural network methods can be used to train models like Málfríður, and neural networks can have different structures or architectures.
Often, it's possible to use models that have already been trained on a large amount of English text, and continue to train on top of them with Icelandic data. This is a common method to avoid having to train models from scratch, with much work and expense. Since the models have been pre-trained, mainly in English, they have gained a lot of knowledge about languages, even though they have seen Icelandic only in passing. Then they need less data to learn Icelandic than if trained from scratch.
After testing different methods and models, we concluded that a model called ByT5 was the model best suited for corrections in Icelandic. This model is pre-trained in English and other languages but very little Icelandic. The uniqueness of this model is that unlike most comparable models, it uses characters (or actually bytes) as building blocks, instead of using subword tokens, as is most common. This method is better suited for correcting an inflectional language like Icelandic, as we have indeed written a scientific paper about.
We first trained this ByT5 model with the synthetic data, to teach it to correct Icelandic texts, and then we fine-tuned it a bit longer on the error corpus only. This fine-tuning is a short training step at the end where a model is trained on high-quality data, which often isn't available in large quantities, to achieve certain behavior. This is an important step in Málfríður, because in this step it gets to learn to correct real errors from real people.
As of writing this in 2024, Málfríður performs better than large language models like ChatGPT, Claude, and Gemini in correcting Icelandic texts. But what is the difference between Málfríður and these large language models?
These are all AI models, but the fundamental difference is that Málfríður is a smaller model specialized in one task: to receive text in Icelandic and output a correct version of the text, in accordance with the training data. Málfríður can't write recipes or resumes or translate text between languages; it only knows how to solve this one task.
Large language models have a different architecture (not encoder and decoder, but only decoder), and are many times larger than Málfríður. Their training is heavy and very expensive, and once completed, they can solve countless tasks in many languages. Some of them have a good understanding of the Icelandic language, but they still lack grammatical knowledge when writing Icelandic text. They have also not received specific information about conventions in Icelandic language use and orthography.
It doesn't always take enormous models to solve specific tasks like language correction, and that's why the ByT5 model we described earlier is useful. We have also applied many tips and tricks for making Málfríður fast in execution and we can control its behavior better than the large models, at least for now.
The development in artificial intelligence is rapid, which is good news for Málfríður, because it means it will only get better over time. It's likely that when large language models become even better at generating Icelandic, Málfríður will utilize their power, among other things to be able to provide explanations for its corrections and refer to sources.
Since Málfríður can't explain its corrections, we have so far mostly had it correct items that are unambiguous errors, but not rephrase text that isn't directly problematic. Suggestions for rephrasing, synonyms, consistency, changes in style, translations, and more suggestions are just a few ideas of what's in the pipeline, so do keep an eye on the development in the future. Málfríður is just beginning to help you write better text!